
Dive Deep into Clone Primitives in Lance Format
In the world of large-scale data management, the ability to efficiently create copies of datasets is crucial for everything from development and testing to data versioning and disaster recovery. Traditional methods like full directory copies are often slow, expensive, and inefficient. Modern data lakehouse formats have introduced more sophisticated solutions, and today, we’re taking a deep dive into the powerful new clone primitives in the Lance format: shallow_clone and deep_clone.
Inspired by the capabilities in Delta Lake, Lance’s clone operations provide first-class support for creating dataset replicas with different trade-offs in terms of speed, storage, and independence. But Lance goes a step further by integrating these primitives with its unique tag and multi-base features, unlocking new possibilities for robust and flexible data management. This article will explore the implementation principles behind these features and show how they form the foundation for even more advanced primitives like branching.
The Foundation: Multi-Base Path Management
Before we can understand cloning, we must first look at a foundational concept in Lance: the multi-base system. At its core, the multi-base feature decouples a dataset’s logical structure from its physical storage layout. A single dataset manifest can reference data files living in completely different physical locations—whether that’s different directories on a local file system or separate buckets in an object store.
Let’s take a quick look on the multi-base protocol:
message Manifest {
......
repeated BasePath base_paths = 18;
}
message BasePath {
uint32 id = 1;
optional string name = 2;
bool is_dataset_root = 3;
string path = 4;
}
message DataFile {
......
optional uint32 base_id = 7;
}
......Lance stores all base path structures in its manifest file so that each data, index, deletion file could use a single optional integer base_id to tell the real base path. If base_id is None, the file will be located under the current dataset root. This protocol enables forward compatibility across multiple base paths and provides effective control over the manifest size.
This simple but powerful mechanism is what makes features like shallow cloning possible. It allows a new dataset point to files of another dataset without moving or copying any data.
Besides, Lance provides multi-base interface in operations for cases people want to extend external storage outside the dataset:
from lance import DatasetBasePath, write_dataset
dataset = lance.write_dataset(data, "s3://primary", mode="create", initial_bases=[DatasetBasePath("s3://archive", name="archive")], target_bases=["archive"])
dataset = lance.write_dataset(more_data, dataset, mode="append", target_bases=["archive"])Fast and Efficient Copies: shallow_clone
A shallow_clone is a metadata-only operation that creates a new, writable dataset version by referencing the data, index, and deletion files of a source dataset. Because it only copies metadata, it is nearly instantaneous and consumes no additional storage for the data itself.
When you perform a shallow clone, Lance creates a new manifest for the target dataset. This new manifest includes a new entry in its base_paths map that points to the URI of the source dataset. All the file metadata from the source version is copied into the new manifest, and the base_id of each file is updated to point to this new entry. The result is a new dataset that starts at the exact same version as the source but is ready for new, independent writes:
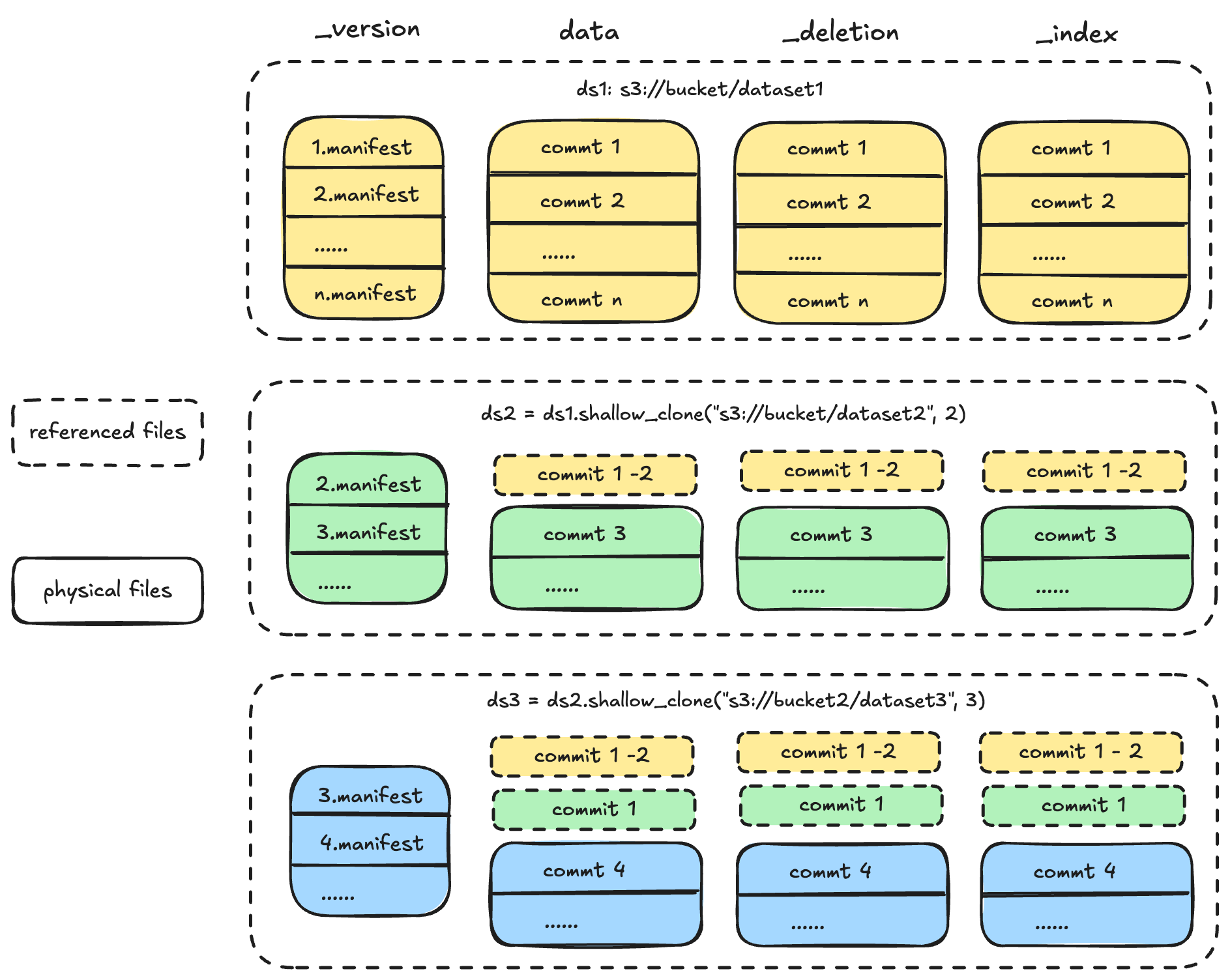
Each cloned dataset begins its independent version history starting from the version it was cloned. It references the source dataset’s data, deletion, and index files. Lance datasets also supports nested shallow_clone operations.
Use Cases and Limitations
Shallow clones are perfect for:
- Development and Testing: Quickly spin up a new environment to test a data transformation or a new model without the cost of a full data copy.
- Short-Term Experiments: Create temporary versions of your data to experiment with different feature engineering pipelines.
However, shallow clones come with a critical limitation: they are not fully independent. The clone maintains a live dependency on the source dataset’s data files. If the source dataset is cleaned up (e.g., using cleanup_old_versions), the files referenced by the clone may be deleted, rendering the clone unusable. This is the same risk associated with shallow_clone in Delta Lake.
In practice: Stability with Tags
This is where Lance’s tag feature provides a significant advantage. Unlike Delta Lake, Lance has a first-class tag primitive that allows you to create a stable, named reference to a specific dataset version. When a version is tagged, Lance’s cleanup operations will not remove the data files associated with it.
By always creating a shallow clone from a tagged version of the source dataset, you can guarantee the long-term stability of the clone’s data sources. This elevates shallow clones from a tool for short-term experiments to a reliable primitive for long-term data management strategies.
Full Independence: deep_clone
For scenarios where complete isolation is required, Lance provides deep_clone. A deep clone is a full physical copy of a specific version of a dataset, including all its data, index, and deletion files. The resulting dataset is completely independent and shares nothing with the source.
While a deep clone is a more expensive operation than a shallow clone, it offers several key advantages over a simple directory copy or a manual read-then-write process:
- Version-Specific Copying: A deep clone only copies the files that are part of the specified source version. For datasets with a long history of appends and updates, this can dramatically reduce the amount of data that needs to be copied compared to a blind copy of the entire directory.
- Server-Side Operations: The deep clone implementation is optimized for cloud object stores. It performs a server-side copy of the files, avoiding the massive performance overhead of downloading the data to a client machine and re-uploading it to the target location.
- Flattening Dependencies: You can perform a deep clone on any dataset, including one that is already a shallow clone or a branch. This provides a powerful way to “flatten” a complex set of dependencies and create a clean, self-contained snapshot.
Conclusion
The addition of shallow_clone and deep_clone brings a new level of flexibility and power to the Lance format. The multi-base architecture provides a robust foundation for these features, while the synergy with tag gives Lance’s shallow clones a unique advantage in stability for long-term use cases.
Furthermore, these clone primitives are not just standalone features; they are the building blocks for even more advanced data management capabilities. For example, Lance’s branch feature is built directly on top of the shallow_clone primitive, providing a Git-like experience for data versioning.
To learn more about how branching works in Lance, stay tuned for our upcoming blog post on the topic.


